P-Values and Confidence Intervals
P-Values and Confidence Intervals are commonly used throughout scientific literature as a means to measure a study’s results. But do you really understand what a ‘P-Value’ denotes and how it differs from a ‘Confidence Interval’? This article explores their definitions, their uses, why they provide complementary types of information and why they aren’t quite what they seem.
Introducing P-Values
Hypothesis Testing: This is used in confirmatory studies where you to test the validity of a claim (the null hypothesis (H0)) that is being made about a population. If the claim is found not to be valid, then we will choose the alternative hypothesis (H1) instead. We can use the P-Value to weigh the strength of evidence and determine if the evidence is statistically significant.
The Null Hypothesis (H0):
This is usually a hypothesis of “no difference”. Each study should have a null hypothesis defined before it begins. Example: “there IS NO difference in blood pressure between placebo and trial groups after taking the medication”.
The Alternative Hypothesis (H1):
This is the hypothesis that you set out to investigate (i.e. the opposite of the null hypothesis). Example: “there IS a difference in blood pressure between placebo and trial groups after taking the medication”.
One-tailed or Two-tailed Hypothesis: A two-tailed hypothesis refers to any difference (either positive or negative effect) whereas a one-tailed hypothesis refers to a directional difference (only looking for a positive or negative effect) when the hypothesis is formulated. A one-tailed hypothesis should be used is when a large change in an unexpected direction would have absolutely no relevance to your study. This is extremely rare, thus a two-tailed hypothesis should be used in most instances.
P-Value: The P-Value is the probability of finding the observed (or more extreme) results when the null hypothesis (H0) of a study question is true. For example, if your P-Value is 0.05, this means in a world where the null hypothesis (H0) is true there is a 5% chance you would see your observed result due to random noise. Thus, the lower the P-Value, the less likely your result is to be caused by noise where the null hypothesis is true.
Significance Level (alpha): This is a term used to refer to an arbitrary pre-chosen probability below which you will reject the null hypothesis (H0). It is the probability of a Type 1 Error you are happy to accept. It is always set before an experiment to avoid bias. Any P-Values below this limit are said to be statistically significant. Commonly seen values include P <0.05 or P<0.01.
Type 1 Error (alpha)
This is the false rejection of the null hypothesis (H0).
Type 2 Error (beta)
This is the false acceptance of the null hypothesis (H0).
Interpretation: If your P-Value is less than the chosen significance level then you reject the null hypothesis (H0). This means in a world where the null hypothesis (H0) is true, it is unlikely your observed results occurred due to random noise. Rather, your data provides reasonable evidence to support the alternative hypothesis (H1). In other words, there is reasonable evidence to support the opposite of the null hypothesis.

Confidence Intervals
Confidence intervals convey more information than P-Values alone; they reflect the results at the level of data measurement. Confidence intervals provide information about a range in which the true value lies with a certain degree of probability, as well as the direction and strength of the demonstrated effect. This enables conclusions to be drawn about the statistical plausibility and clinical relevance of the study findings. So, what is a confidence interval?
Confidence Interval
This is a range of values calculated by statistical methods which includes the desired true parameter with a probability defined in advance (usually the confidence level).
Confidence Level
The confidence level sets the boundaries of the confidence interval. It is conventionally set at 95% to coincide with the 5% convention of statistical significance in hypothesis testing.
95% Confidence Interval: This is the interval that you are 95% certain contains the true population value as it might be estimated from a much larger study. One interpretation of this is that the interval will contain the true value on 95% of occasions if a study were repeated many times using samples from the same population.
Dependencies: The size of the confidence interval depends upon the sample size and the standard deviation of the study groups. If the sample size is large, there is more confidence and thus a narrower confidence interval. If the dispersion of results is high, the conclusion is less certain, and the confidence intervals become wider. The confidence level will influence the width of the confidence interval with a higher level of confidence requiring a wider confidence interval.
Direction Effect and Statistical Significance: Conclusions about statistical significance are possible using confidence intervals because they indicate the direction of effect. If the confidence interval does not include the value of zero effect, it can be assumed there is a statistically significant result.
Final Thoughts: Values below the lower limit or above the upper limit are not excluded but are improbable. Values within the confidence limits, but near to the limits, are less probable than values near the point estimate (usually the mean difference) where the point estimate is the best approximation for the true value for the population.
P-Value Controversies
P-Values are somewhat of a controversial topic within the realm of statisticians. Multiple articles have been published which denounce their improper use, including one popular article “Scientific Method: Statistical Errors” published within Nature in 2014. The uproar created by all of these articles spurred the American Statistical Association (ASA) to publish a consensus statement on P-Values in 2016. Both articles are worth reading and taking some time to mull over. What follows is a summary of these articles.
In February 2014 a professor of mathematics and statistics asked two questions: “Why do so many colleges and grad schools teach p = 0.05?”. The reply came as “Because that’s still what the scientific community and journal editors use”. Next, he asked “Why do so many people still use p = 0.05?”. The reply came as “Because that is what they were taught in college or grad school”. In other words, we teach it because it’s what we do; we do it because it’s what we teach.
Historical Beginnings
The story begins with Ronald Fisher in the 1920s. He created the P-Value as an informal way to judge whether the evidence was significant ‘in the old-fashioned’ sense. In other words, was the evidence worthy of a second look? The idea was to run an experiment and see if the results were consistent with what random chance might produce. This experiment materialised itself as what is now known as the ‘hypothesis test’. Researchers would set a ‘null hypothesis’ that they wanted to disprove. They would then play devil’s advocate by assuming this null hypothesis was in fact true and calculate the chances of getting results at least as extreme as what was actually observed. This probability is known as the P-Value. The smaller the P-Value, the greater the likelihood the null hypothesis was false.
Meanwhile other statisticians, namely Jerzy Neyman and Egon Pearson, were proposing alternative statistical methods for data analysis such as false positives and so forth. As the statisticians argued over the best way to statistically present data, practicing scientists got on and produced statistical manuals for their own use. The scientists combined an array of statistical concepts to create the methods commonly used in research today. One result of this practical adoption was the enshrining of P-Values with ‘statistically significant’ results. Unfortunately, the scientists were not statisticians and some of their suggestions have resulted in the use of statistical tools in ways that were not intended.
Misinterpretations
While the P-Value can be a useful statistical measure, it is commonly misused and misinterpreted. This can lead to issues with reproducibility and replicability of scientific conclusions.
One common misinterpretation is the notion that a ‘P-Value of 0.01 means there is a 1% chance of the results being a false alarm’. This is wrong. All the P-Value can do is summarise the probability of finding the observed (or more extreme) results when the null hypothesis of a study question is true. This misinterpretation is rooted in the assumption that it is possible to work backwards from the P-Value and make statements about the underlying reality. This is wrong. To make a statement about the underlying reality would require the odds that a real effect was there in the first place. Thus, the more implausible the null hypothesis (i.e. smaller odds that a real effect was there), the greater the chance that an exciting finding is a false alarm, no matter what the P-Value is (see probable cause below).
A further problem with P-Values is that they deflect attention from the actual size of an effect and do not indicate the practical relevance of the findings. For example, the P-Value may be statistically significant, but the observed effect may actually be so minimal that it would have little to no impact on the real-world application of the study. Think about a medication which has a statistically significant impact (P<0.01) on increasing the life expectancy of a patient by 3 days. This medication, although shown to confer a small survival benefit, may well not be cost-effective nor acceptable with the side-effect profile. The P-Value does not answer the all-important question “How much of an effect is there?”.
A further problem is many researchers have been found to manipulate their data, both consciously and unconsciously, to uncover statistically significant P-Values. This is known as P-Hacking. Essentially, they try many different combinations of analysis until they get the desired result.
Possible Solutions
So, what can be done? Well, researchers should always report the effect sizes and the confidence intervals of their results. This conveys the magnitude and relative importance of an effect. Additionally, researchers might consider using methods that include Bayes’ rule to describe the probability as the plausibility of an outcome rather than as the potential frequency of that outcome (see probable cause below). This does include some subjectivity, but it will allow observers to incorporate what they know about the world into their conclusions. This method involves bringing elements of scientific judgement about the plausibility of a hypothesis and study limitations into their analysis. Alternatively, researchers could perform a two-stage analysis where an exploratory study is performed to gather interesting findings and then a confirmatory study is planned, publicly pre-registered on a database and then performed as per the registered protocol. This allows freedom and flexibility in the study design while ensuring data is not manipulated in an effort to find a significant result. Finally, the most important thing that researchers can do is to admit everything. They should report how they determined their sample size, describe all data exclusions (if any), describe all manipulations and describe all measures within the study. Remember, the numbers are where the scientific discussion should start, not end.
Probable Cause
Probable cause helps answer the question ‘What the odds are that a hypothesis is correct?’. The answer for this will depend upon how strong the result was and how plausible the hypothesis was in the first place. A small P-Value can make a hypothesis more plausible, but the effect is not dramatic. The real effect lies within the plausibility of the hypothesis to begin with. The impact on plausibility of real effect by P-Values and the hypothesis original odds is explored in the diagram below.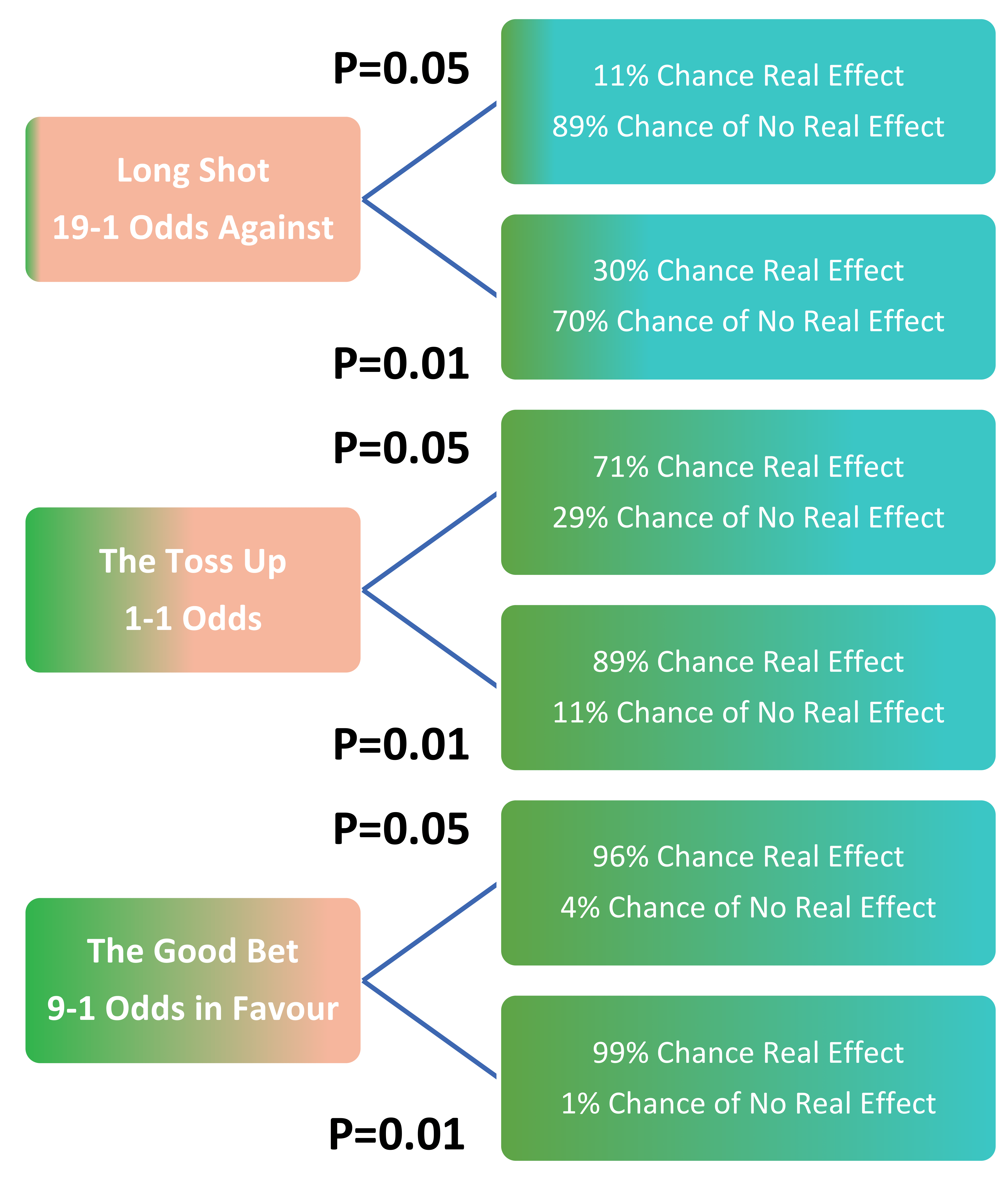
Principles of ASA Statement on P-Values
- P-Values can indicate how incompatible the data are with a specified statistical model (i.e. the null hypothesis).
- The smaller the P-Value, the greater the statistical incompatibility of the data with the null hypothesis provided the underlying assumptions used to calculate the P-Value hold.
- This incompatibility can be interpreted as casting doubt on or providing evidence against the null hypothesis and its underlying assumptions.
- P-Values do not measure the probability that the studied hypothesis is true, nor the probability that the data were produced by random chance alone.
- The P-Value is a statement about data in relation to a specified hypothetical explanation and is not a statement about the explanation itself.
- Scientific conclusions and business or policy decisions should not be based only on whether a P-Value passes a specific threshold.
- Such practices can lead to erroneous beliefs and poor decision making.
- P-Values alone cannot ensure a decision is correct or incorrect. A conclusion does not immediately become true on one side of the divide and false on the other.
- You should consider different contextual factors to derive scientific inferences. Consider the design of a study, the quality of the measurements, the external evidence for the phenomenon and the validity of assumptions that underlie the data analysis.
- Proper inference requires full reporting and transparency.
- P-Values and related analyses should not be reported selectively. Conducting multiple analyses of the data and reporting only certain P-Values renders the reported P-Values uninterpretable. This is cherry picking!
- If a researcher chooses what to present based on statistical results, the valid interpretation of those results is severely compromised if the reader is not informed of the choice and its basis.
- Researchers should disclose the number of hypotheses explored during the study, all data collection decisions, all statistical analyses performed, and all P-Values computed.
- Valid conclusions based on P-Vales cannot be drawn without knowing how many analyses were conducted, which analyses were conducted and how those analyses were selected for reporting.
- A P-Value, or statistical significance, does not measure the size of an effect or the importance of a result.
- Small P-Values do not imply the presence of larger or more important effects.
- Any effect, not matter how tiny, can produce a small P-Value if the sample size or measurement precision is high enough. Large effects may produce unimpressive P-Values if the sample size is small or measurements imprecise.
- By itself, a P-Value does not provide a good measure of evidence regarding a model or hypothesis.
- P-Value without context or other evidence provides limited information.
- P-Value of 0.05 only offers weak evidence against the null hypothesis.
- A large P-Value does not imply evidence in favour of the null hypothesis. Many other hypotheses may be consistent with the observed data.
- Data analysis should not end with a calculation of a P-Value when other approaches are appropriate and feasible.